Continuing my exploring methods for spatial visualisation of data in R, today I’m looking at linked micromaps. Micromaps are a way of showing statistical graphics for a small subset of regions at a time, with a small map indicating which regions are being looked at in each of the small multiples. Alberto Cairo has some nice discussion in this blog post.
Poverty and education in the USA
It’s easier to show than explain. Here’s one I’ve adapted from the helpfiles of the R micromaps package by Quinn Payton, Tony Olsen, Marc Weber, Michael McManus and Tom Kincaid of the US Environmental Protection Agency and generously open-sourced by that agency. Under the hood, micromaps uses Hadley Wickham’s ggplot2 to create the graphic assets and (I think) Paul Murrell’s grid to lay them out in aligned fashion.

Some links for the micromaps package:
- Production version on CRAN
- Introductory article in the Journal of Statistical Software
- Source code on the USEPA GitHub page
I used this USA example as my test case for understanding the micromaps API. Some of the changes I’ve introduced here include:
- Set my own font
- Pale blue background with white gridlines to make them go into the background, ggplot2-style.
- White borders for the grey-fill states that have been previously drawn, so the border lines don’t distract the eye from the five states being referred to in each cluster.
- Tidied up the code for readability
Here’s the code that draws this, and sets up the overall session. Note that the nzcensus (by me) and mbiemaps (by New Zealand’s Ministry of Business, Innovation and Employment, my previous employer) are only available on GitHub, not CRAN. Code to install them is available in a previous post. They’re needed for New Zealand data and maps later on.
library(micromap)
library(nzcensus)
library(extrafont)
library(mbiemaps) # for the territorial authority map
library(tidyverse)
library(testthat)
library(scales)
library(ggrepel)
the_font <- "Calibri"
theme_set(theme_minimal(base_family = the_font))
#============polish up the example from the ?lmplot helpfile===============
data("USstates")
data("edPov")
# convert from SpatialPolygonsDataFrame into a data frame (similar to fortify)
statePolys <- create_map_table(USstates, 'ST')
# draw graphic
lmplot(stat.data = edPov,
map.data = statePolys,
panel.types = c('labels', 'dot', 'dot','map'),
panel.data = list('state','pov','ed', NA),
ord.by = 'pov',
grouping = 5,
colors = brewer.pal(5, "Spectral"),
median.row = TRUE,
# how to merge the two data frames:
map.link = c('StateAb', 'ID'),
# stroke colour of the borders of previously-drawn areas:
map.color2 = "white",
# how to save the result:
print.file = "0095-eg1.png",
print.res = 600,
plot.width = 7,
plot.height = 9,
# attributes of the panels:
panel.att = list(
list(1, header = "States",
panel.width = 0.8,
text.size = 0.8,
align = 'right',
panel.header.font = the_font,
panel.header.face = "bold",
text.font = the_font,
left.margin = 2,
right.margin = 1),
list(2, header = "Percent living below\npoverty level",
xaxis.title = 'Percent',
xaxis.ticks = list(10, 15, 20),
xaxis.labels = list(10, 15, 20),
graph.bgcolor = 'lightblue',
graph.grid.color = "grey99",
graph.border.color = "white",
panel.header.font = the_font,
panel.header.face = "bold"),
list(3, header = "Percent adults with\n4+ years of college",
xaxis.title = 'Percent',
xaxis.ticks = list(0, 20, 30, 40),
xaxis.labels = list(0, 20, 30, 40),
graph.bgcolor = 'lightblue',
graph.grid.color = "grey99",
graph.border.color = "white",
panel.header.font = the_font,
panel.header.face = "bold"),
list(4, header = 'Light gray means\nhighlighted above',
panel.width = 0.8,
panel.header.font = the_font,
panel.header.face = "italic")
))Most of the polishing code is in the list of lists passed to the panel.att argument. Each list refers to the attributes of one of the four panels (state names, poverty dot charts, education dot charts, maps). I had to do a bit of digging to find out how to control things like grid colour; while doing this it was useful to run one of the three lines of code below to see what attributes are within your control for the different panel types:
unlist(labels_att(TRUE) )
unlist(dot_att(TRUE) )
unlist(map_att(TRUE) )Note that the lmplot function specifies a file to print the graphic to. I don’t like this, as it’s breaks some commonly accepted R workflows. For example, for this blog I usually create in advance all the graphics for each post in SVG format, which scales up nicely if people zoom in on it and is generally the best format (my view) for web graphics. That can’t be done when lmplot restricts you to particular device types. The pattern also doesn’t work well with Yixuan Qiu’s showtext R package that I normally use for fonts (it lets me access Google fonts, including the Poppins font I use for most graphics).
New Zealand census example
To be sure I understood how to use the technique, I wanted to apply it to some New Zealand maps and data. I’m used to presenting data at the Territorial Authority level in New Zealand by means of a choropleth map like this one:
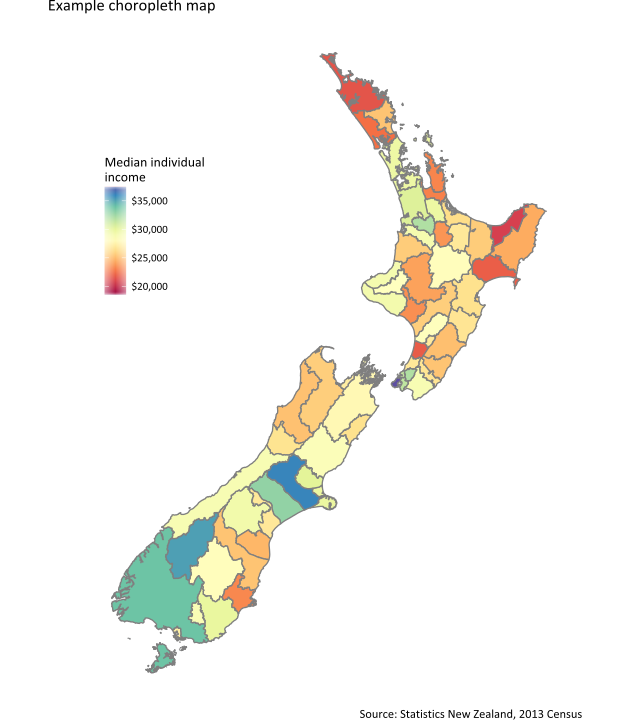
… which was drawn with this code, using the TA2013 data frame of 2013 census data from my nzcensus package:
# pre-fortified data frame version of TA level map, from mbiemaps package:
data(ta_simpl_gg)
# change name in census data to match the name used in ta_simpl_gg
TA2013$short_name <- gsub(" District", "", TA2013$TA2013_NAM)
# filter out some visually inconvenient data:
ta_data <- TA2013 %>%
filter(!short_name %in% c("Chatham Islands Territory", "Area Outside Territorial Authority")) %>%
mutate(PercNoReligion = PropNoReligion2013 * 100)
# draw map:
ta_simpl_gg %>%
left_join(ta_data, by = c("NAME" = "short_name")) %>%
arrange(order) %>%
ggplot(aes(x = long, y = lat, group = group, fill = MedianIncome2013)) +
geom_polygon(colour = "grey50") +
ggmap::theme_nothing(legend = TRUE) +
theme(legend.position = c(0.2, 0.7)) +
scale_fill_gradientn("Median individual\nincome",
colours = brewer.pal(11, "Spectral"), label = dollar) +
coord_map(projection = "sinusoidal") +
ggtitle("Example choropleth map") +
labs(caption = "Source: Statistics New Zealand, 2013 Census")Doing this with a linked micromap instead of a choropleth map lets us look at more variables at once, but I can’t say I’m happy with the result:
My reservations about this graphic:
- It feels like there are just too many territorial authorities for this to be a really friendly graphic.
- Also, my map of New Zealand is probably too crinkly and individual districts and cities too small to show up well.
- There’s an awkwardness of New Zealand being tall rather than wide - a smaller aspect ratio than USA. This seems to make the New Zealand map less well suited to the technique than the USA map.
- It’s hard for the reader to move their eyes back and forth from the district or city name to the dots and to the map.
- I couldn’t work out how (if it is possible) to control the projection of the map, and hence New Zealand looks a little bit stretched and rotated.
Here’s the code that drew this, anyway:
# change names of the map data frame to meet lmplot's expectations
ta_polys2 <- ta_simpl_gg %>%
rename(coordsx = long,
coordsy = lat,
ID = NAME) %>%
mutate(hole = as.numeric(hole),
plug = 0,
region = as.numeric(as.factor(ID)))
# check merge will be ok
a <- unique(ta_polys2$ID) # names of map polygons
b <- unique(ta_data$short_name) # names of TAs with census data
expect_equal(a[!a %in% b], b[!b %in% a])
# draw graphic:
lmplot(stat.data = ta_data,
map.data = ta_polys2,
panel.types = c('labels', 'dot', 'dot','map'),
panel.data = list('short_name','MedianIncome2013','PercNoReligion', NA),
ord.by = 'MedianIncome2013',
grouping = 6,
median.row = FALSE,
# how to merge the two data frames:
map.link = c('short_name', 'ID'),
# stroke colour of the borders of previously-drawn areas:
map.color2 = "white",
# how to save the result:
print.file = "0095-eg2.png",
print.res = 600,
plot.width = 14,
plot.height = 18,
# attributes of the panels:
panel.att = list(
list(1, header = "Territorial Authorities",
panel.width = 1.2,
panel.header.size = 2,
text.size = 1.6,
align = 'right',
panel.header.font = the_font,
panel.header.face = "bold",
text.font = the_font,
left.margin = 2,
right.margin = 1,
xaxis.title.size = 2),
list(2, header = "Median\nincome",
panel.header.size = 2,
xaxis.title = 'Dollars',
xaxis.title.size = 2,
xaxis.labels.size = 2,
graph.bgcolor = 'grey80',
graph.grid.color = "grey99",
graph.border.color = "white",
panel.header.font = the_font,
panel.header.face = "bold",
point.border = FALSE,
point.size = 2),
list(3, header = "Percent individuals\nwith no religion",
panel.header.size = 2,
xaxis.title = 'Percent',
xaxis.title.size = 2,
xaxis.labels.size = 2,
graph.bgcolor = 'grey80',
graph.grid.color = "grey99",
graph.border.color = "white",
panel.header.font = the_font,
panel.header.face = "bold",
point.border = FALSE,
point.size = 2),
list(4, header = '\n',
panel.header.size = 2,
panel.width = 0.5,
panel.header.font = the_font,
panel.header.face = "italic",
active.border.size = 0.2,
withdata.border.size = 0.2,
nodata.border.size = 0.2)
))Now, there’s a standard way of showing two variables against each other. We lose the spatial element, but for most purposes I think the good old scatter plot is better for this data:

…drawn with:
ta_data %>%
ggplot(aes(x = MedianIncome2013, y = PropNoReligion2013, label = short_name)) +
scale_x_continuous("Median income", label = dollar) +
scale_y_continuous("No religion", label = percent) +
geom_smooth(method = "lm", colour = "white") +
geom_point(aes(size = CensusNightPop2013), shape = 19, colour = "grey60") +
geom_point(aes(size = CensusNightPop2013), shape = 1, colour = "black") +
geom_text_repel(colour = "steelblue", size = 2.5) +
scale_size_area("Census night population", max_size = 10, label = comma) +
theme(legend.position = "bottom") +
labs(caption = "Source: Statistics New Zealand, census 2013")Maybe better with a smaller number of areas?
New Zealand has 66 districts and cities (not counting Chatham Islands), but only 16 Regional Councils. Perhaps the method works better with a smaller number of areas to show:
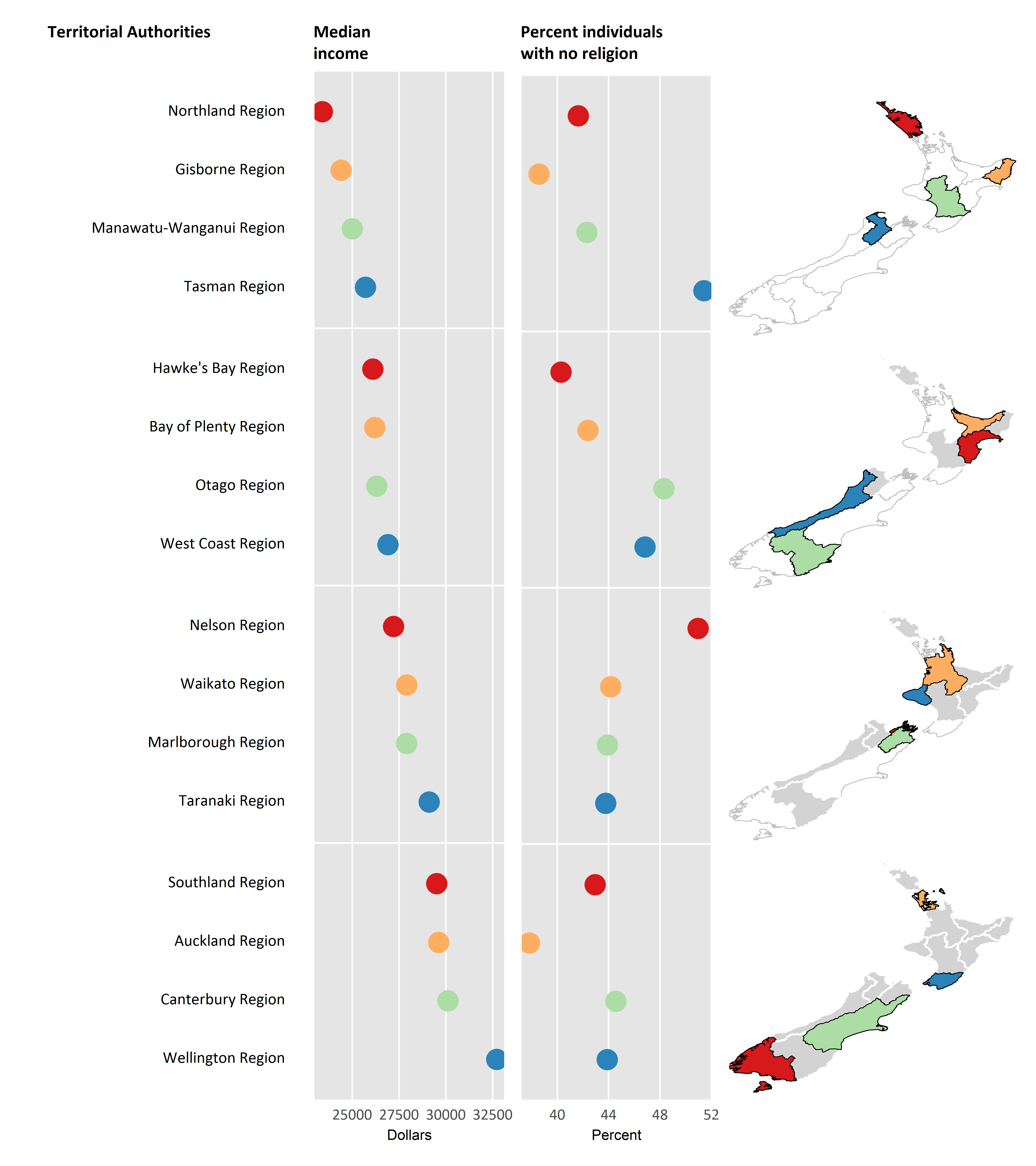
… and I think that probably is ok. But really, all we are showing here is 32 numbers. It’s an expensive graphic for something that could almost be as meaningfully shown in a table. All up, my reaction to linked micromaps is one of caution. Like any visualisation tool, I think they’ll be good in some circumstances, but in others they just won’t seem to easily communicate.
Code for the regional council micromap:
#================regions example============
# convert from SpatialPolygonsDataFrame into a data frame (similar to fortify)
data(region_simpl) # map from mbiemaps
reg_polys <- create_map_table(region_simpl, 'NAME')
reg_data <- REGC2013 %>%
mutate(PercNoReligion = PropNoReligion2013 * 100) %>%
filter(REGC2013_N != "Area Outside Region")
lmplot(stat.data = reg_data,
map.data = reg_polys,
panel.types = c('labels', 'dot', 'dot','map'),
panel.data = list('REGC2013_N','MedianIncome2013','PercNoReligion', NA),
ord.by = 'MedianIncome2013',
grouping = 4,
median.row = FALSE,
# how to merge the two data frames:
map.link = c('REGC2013_N', 'ID'),
# stroke colour of the borders of previously-drawn areas:
map.color2 = "white",
# how to save the result:
print.file = "0095-eg3.png",
print.res = 600,
plot.width = 8,
plot.height = 9,
# attributes of the panels:
panel.att = list(
list(1, header = "Territorial Authorities",
panel.width = 1.2,
text.size = 0.8,
align = 'right',
panel.header.font = the_font,
panel.header.face = "bold",
text.font = the_font,
left.margin = 2,
right.margin = 1),
list(2, header = "Median\nincome",
xaxis.title = 'Dollars',
panel.width = 0.8,
left.margin = .5,
right.margin = .5,
graph.bgcolor = 'grey90',
graph.grid.color = "grey99",
graph.border.color = "white",
panel.header.font = the_font,
panel.header.face = "bold",
point.border = FALSE,
point.size = 2.5),
list(3, header = "Percent individuals\nwith no religion",
panel.width = 0.8,
left.margin = .5,
right.margin = .5,
xaxis.title = 'Percent',
graph.bgcolor = 'grey90',
graph.grid.color = "grey99",
graph.border.color = "white",
panel.header.font = the_font,
panel.header.face = "bold",
point.border = FALSE,
point.size = 2.5),
list(4, header = '\n',
panel.width = 1.2,
panel.header.font = the_font,
panel.header.face = "italic",
active.border.size = 0.5,
withdata.border.size = 0.5,
nodata.border.size = 0.5)
))Bonus - area unit cartograms
Finally, an aside. My last two blog posts have been about what you might call population-weighted carto-choro-pletho-grams… I’ve been gradually enhancing this Shiny web app which lets people play around with visualisations of 2013 census data. Latest addition is data at the detailed area unit level. Here’s a screenshot showing which area units have higher proportions of people with a background from the Pacific islands:

Check out the full app for more.